
DeepMind’s AI can ‘˜imagine’ a world based on a single picture | Tech News
Udo Siebig/ALAMY
Artificial intelligence can now put itself in someone else’s shoes. DeepMind has developed a neural network that taught itself to ‘imagine’ a scene from different viewpoints, based on just a single image.
Given a 2D picture of a scene – say, a room with a brick wall, and a brightly coloured sphere and cube on the floor – the neural network can generate a 3D view from a different vantage point, rendering the opposite sides of the objects and altering where shadows fall to maintain the same light source.
The system, called the Generative Query Network (GQN), can tease out details from the static images to guess at spatial relationships, including the camera’s position.
Advertisement
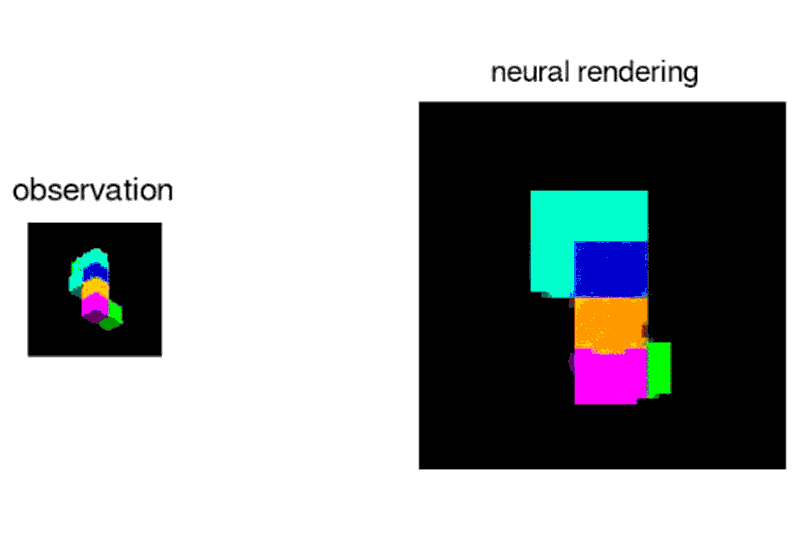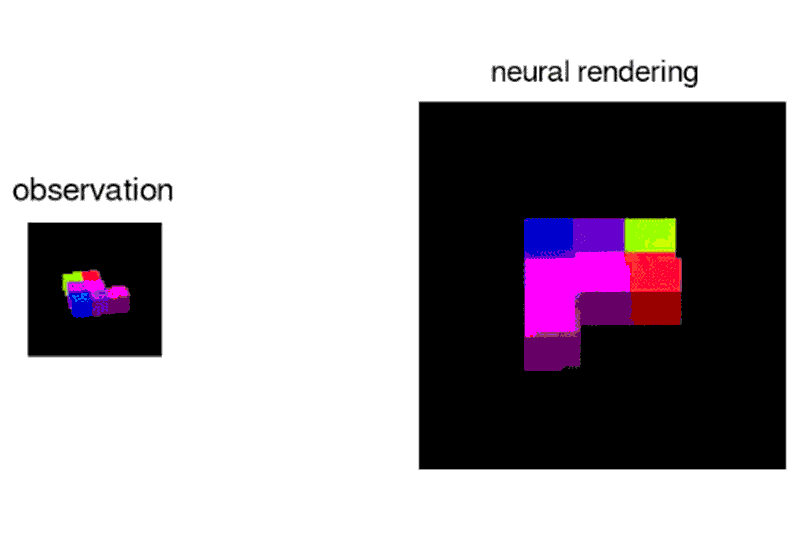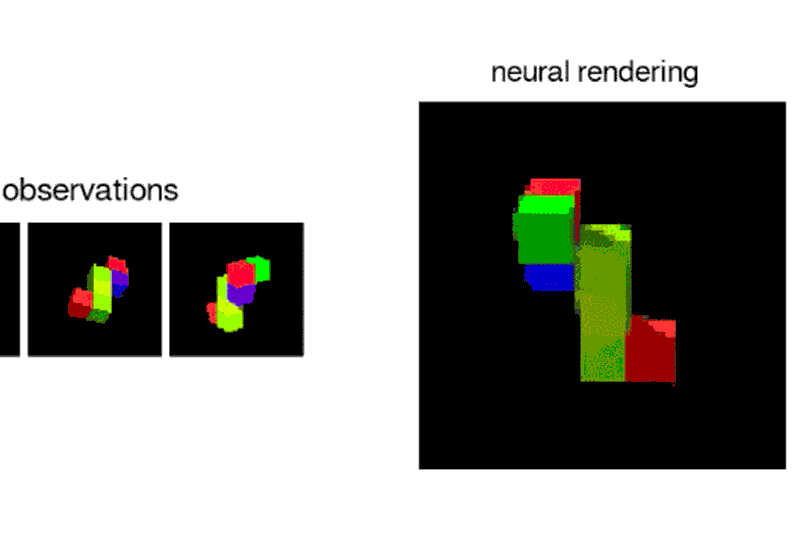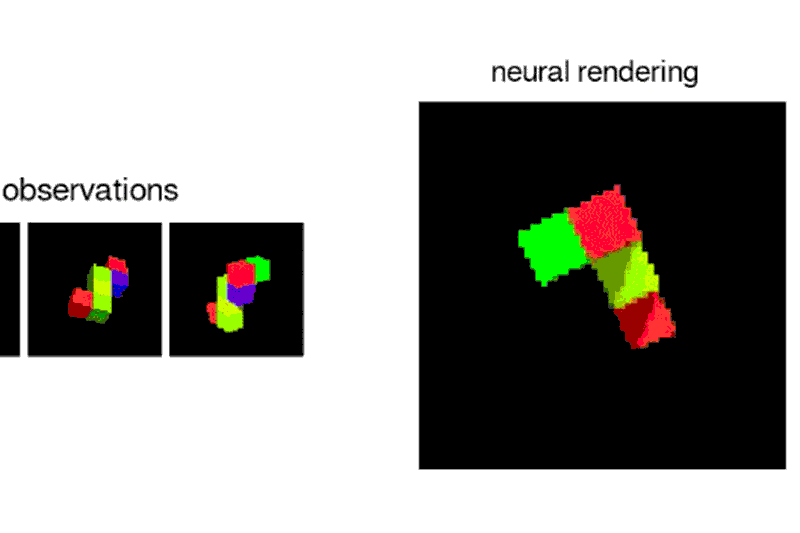
“Imagine you’re looking at Mt. Everest, and you move a metre – the mountain doesn’t change size, which tells you something about its distance from you,”says Ali Eslami who led the project at Deepmind.
“But if you look at a mug, it would change position. That’s similar to how this works,”
To train the neural network, he and his team showed it images of a scene from different viewpoints, which it used to predict what something would look like from behind or off to the side. The system also taught itself through context about textures, colours, and lighting. This is in contrast to the current technique of supervised learning, in which the details of a scene are manually labeled and fed to the AI.
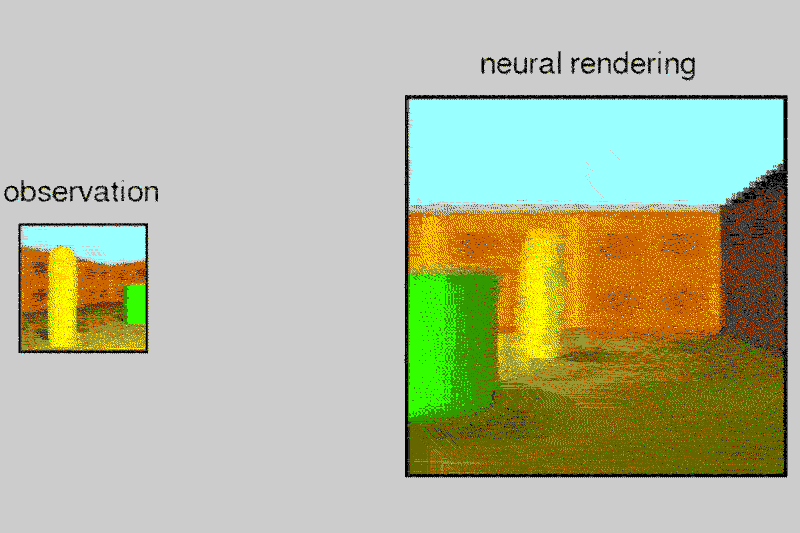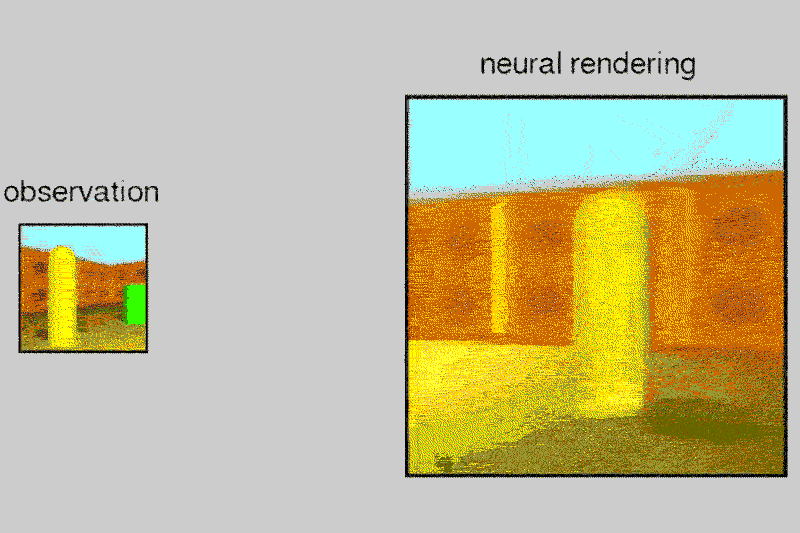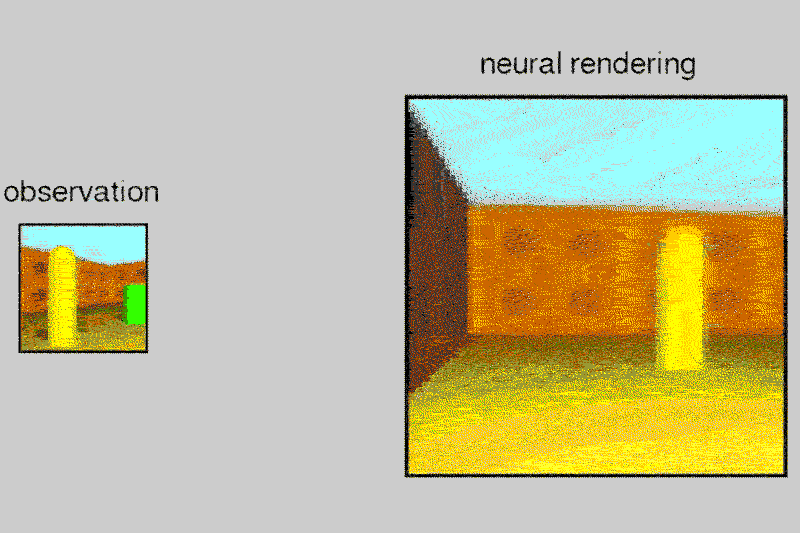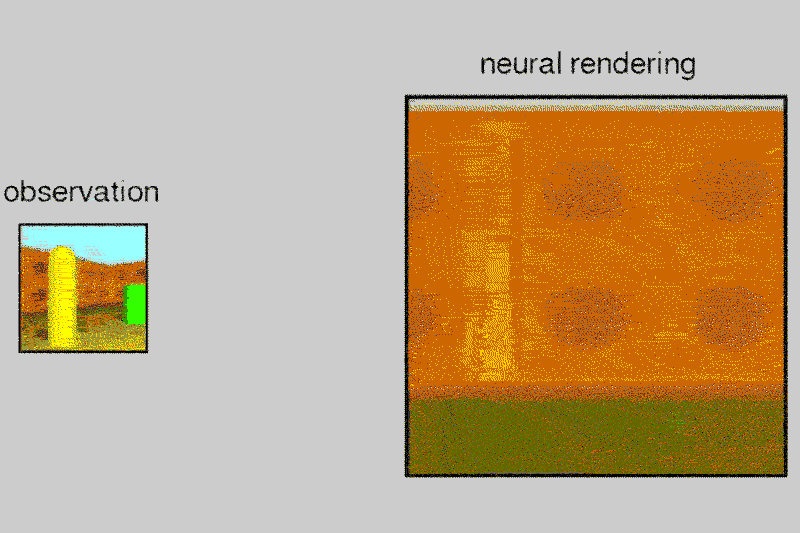
The AI can also control objects in virtual space, applying its understanding of spatial relationships to a scenario where it moved a robotic arm to pick up a ball. It learns a lot like we do, even if we don’t realise it, says Danilo Rezende at DeepMind, who also worked on the project.
By showing the neural network many images in training, it can suss out the characteristics of similar objects and remember them. “If you look inside the model, we can identify groups of artificial neurons, units in the computational graph, that represent the object,” Rezende says.
The system moves around these scenes, making predictions about where things should be and what they ought to look like, and adjusting when its predictions are incorrect.
It was able to use this ability to work out the layout of a maze after seeing just a few pictures of it taken from different viewpoints.

Journal reference: Science, DOI: 10.1126/science.aar6170
Read more: The rapid rise of neural networks and why they’ll rule our world
More on these topics:
Comments are closed.